Last Updated on 01 Apr 2026
OWASP A09:2025 Security Logging and Alerting Failures Prevention Guide
Share in
Introduction
OWASP Top 10 remains one of the most widely used reference points for application security because it translates a very large and fast moving threat landscape into a practical list of risks that product teams, developers, architects, fraud teams, and security leaders can act on. In the 2025 release, OWASP again places A09, Security Logging and Alerting Failures, at number nine and notes that this category is difficult to test, underrepresented in CVE and CVSS data, yet highly impactful for visibility, incident alerting, and forensics. OWASP's score table for A09 reports 5 mapped CWEs, a maximum incidence rate of 11.33%, an average incidence rate of 3.91%, total occurrences of 260,288, and 723 CVEs.
That matters because modern fraud and breach activity rarely fails loudly. In many real incidents, the core problem is not that logs do not exist, but that they are incomplete, low context, poorly retained, scattered across tools, or never turned into actionable alerts. IBM's 2025 Cost of a Data Breach report says the global average breach cost is USD 4.4 million, and IBM reports an average breach lifecycle of 241 days to identify and contain. If an organization still treats logging as a passive archive instead of an active detection layer, it leaves an attacker far too much time to move, persist, and monetize access.
A09 also intersects directly with fraud prevention. Verizon's 2025 DBIR says that about 88% of breaches in the Basic Web Application Attacks pattern involved stolen credentials. That means login flows, failed logins, impossible travel, session anomalies, device changes, and abnormal behavior are not peripheral telemetry anymore. They are often the only early warning signs that a valid looking session is actually a compromised one.
For that reason, one of the strongest practical recommendations for A09 today is continuous monitoring of user behavior, device identity, and session context. Logging more is useful, but logging alone does not solve the hardest problem. The harder problem is detecting the one dangerous pattern hidden inside millions of normal events, then doing it quickly enough to matter.
Top 10:2025 List
•
A01:2025 Broken Access Control
This category covers failures that let users act outside their intended permissions, such as viewing, modifying, or deleting resources they should not reach. It remains dangerous because one small authorization gap can expose entire datasets or admin capabilities.•
A02:2025 Security Misconfiguration
This risk appears when systems, cloud services, frameworks, or controls are deployed with unsafe defaults or inconsistent settings. It is common because fast shipping often outpaces hardening, validation, and review.•
A03:2025 Software Supply Chain Failures
This category focuses on weaknesses introduced through dependencies, build pipelines, third party components, and update channels. It is dangerous because trusted software paths can become attack paths.•
A04:2025 Cryptographic Failures
These failures happen when sensitive data is not protected correctly in storage, transit, or key management. The risk is not only exposure of data, but also reuse of secrets, tokens, and session material by attackers.•
A05:2025 Injection
Injection occurs when untrusted input is interpreted as commands or queries by a backend component. Even mature teams still face it because legacy endpoints, complex parsers, and overlooked parameters create openings.•
A06:2025 Insecure Design
This category addresses flaws in workflows, trust boundaries, business logic, and architecture rather than simple coding defects. Clean code cannot compensate for a design that never modeled abuse correctly.•
A07:2025 Authentication Failures
These failures arise when authentication, session handling, or identity assurance is too weak for the threats involved. In practice, many attacks succeed after login, not before it, which makes continuous verification essential.•
A08:2025 Software or Data Integrity Failures
This risk covers misplaced trust in code, updates, pipelines, and data flows that can be altered or abused. The danger comes from treating a source as trusted long after the trust assumption should have been revalidated.•
A09:2025 Security Logging and Alerting Failures
This category covers missing logs, weak monitoring, poor alerting, tamperable audit trails, and ineffective response escalation. It is especially damaging because organizations may not realize they are under attack until long after the attacker has achieved the objective.•
A10:2025 Mishandling of Exceptional Conditions
This category concerns errors, edge cases, and unusual system states that are processed unsafely or invisibly. When systems fail noisily for users but silently for defenders, attackers gain cover.
Definition and Causes of Security Logging and Alerting Failures
A09:2025 Security Logging and Alerting Failures is the condition in which an application cannot produce, protect, correlate, escalate, and act on the evidence needed to recognize abuse or investigate it later. OWASP explains that without logging and monitoring, attacks and breaches cannot be detected, and without alerting it becomes very difficult to respond quickly and effectively during a security incident. The category includes missing logs for auditable events, weak or unclear error messages, poor protection of log integrity, failure to monitor application and API logs, local only storage, weak escalation thresholds, weak real time detection, sensitive data leakage through logs, improper log encoding, missing alert use cases, too many false positives, and outdated or missing playbooks.
In practical terms, A09 is not just a security engineering weakness. It is also a fraud operations weakness, a compliance weakness, and a business visibility weakness. If failed logins are not recorded with enough context, credential abuse blends into normal noise. If high value account changes are not monitored, an attacker can pass MFA, hijack a session, and move through sensitive workflows while the system keeps treating the session as trusted. If exceptional conditions are swallowed silently, the platform may not even know that security relevant failures occurred.
OWASP's score table shows why the category deserves more attention than its CVE count suggests. A09 keeps its position at number nine, has 260,288 total occurrences in the dataset, and remains community voted because it is hard to test systematically even though the operational impact is large. In other words, A09 is often not the breach itself. It is the reason the breach stays invisible long enough to become expensive.
There is also a regulatory dimension. GDPR Article 32 requires technical and organizational measures appropriate to the risk, including ongoing confidentiality, integrity, availability, resilience, and a process for regularly testing and evaluating security measures. GDPR Article 33 further requires breach notification within 72 hours where feasible, and documentation of breaches. That means weak detection and weak internal reporting can become compliance failures in addition to security failures.
Variations of Security Logging and Alerting Failures
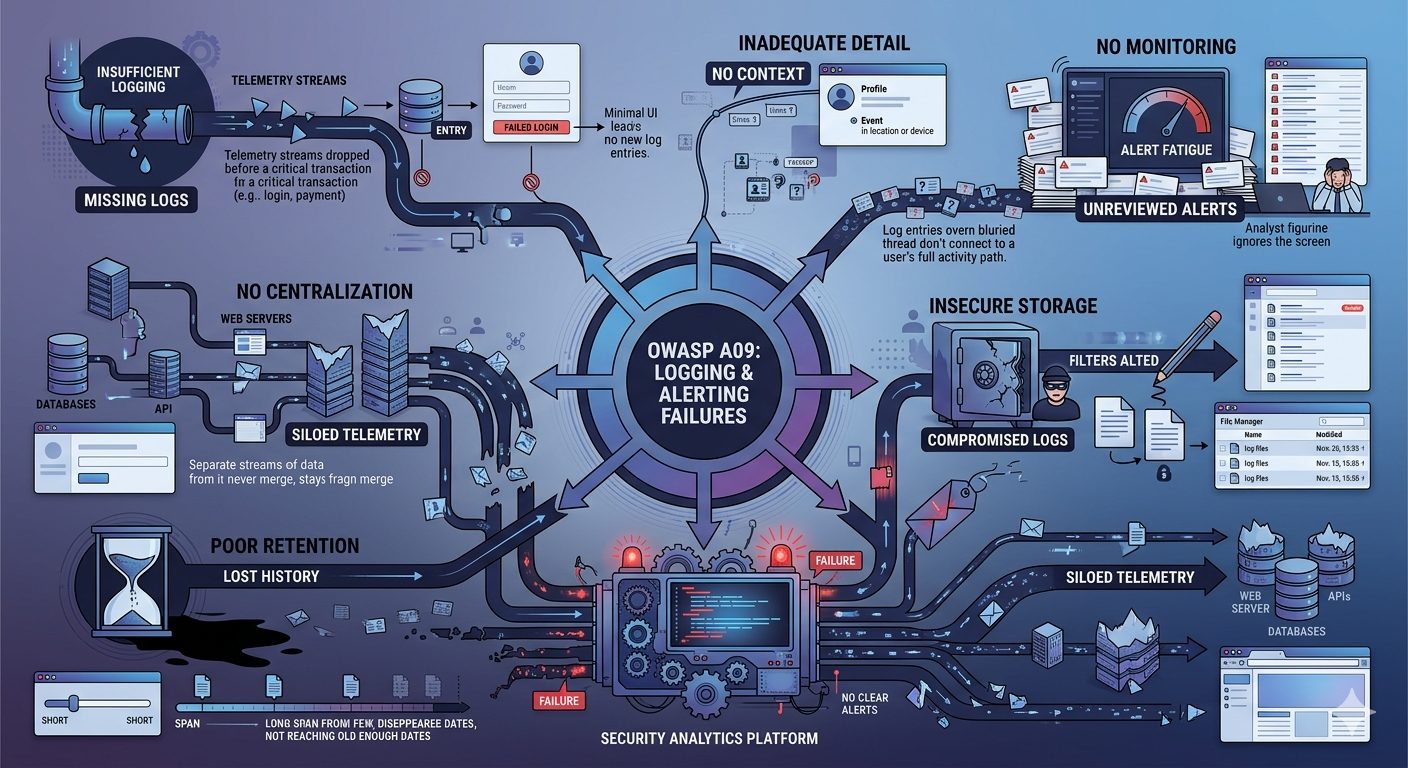
Insufficient logging means critical security events are not captured at all, or are logged so inconsistently that investigators cannot reconstruct what happened. OWASP explicitly calls out missing logs for logins, failed logins, high value transactions, and server side validation failures. In real systems, this usually appears when infrastructure logging exists but application event logging is shallow, disabled, or never designed for abuse cases. The result is predictable: the team has data, but not the right data.
The business impact is larger than many teams expect. Verizon's 2025 DBIR says roughly 88% of breaches in the Basic Web Application Attacks pattern involved stolen credentials, which means login and session level telemetry is often the first place abuse becomes visible. If those events are not logged with enough coverage, the organization loses its earliest and most actionable signal.
2. Inadequate Detail
A log that records an event without useful context often fails almost as completely as a missing log. Timestamps without user identifiers, user identifiers without device context, or alert records without the triggering workflow create evidence that is too thin to support response or forensics. OWASP highlights the need for sufficient user context, and PCI guidance similarly emphasizes review of security events to identify anomalies and suspicious behavior.
This matters because attackers increasingly blend into allowed behavior. A login from the right geography may still be fraudulent if the device is unfamiliar, the session path is abnormal, or the user behavior is inconsistent with historical patterns. Without richer context, the detection team cannot tell the difference between a high value customer and a high value attacker.
3. No Monitoring
Some organizations generate logs correctly and still fail A09 because nobody actively reviews them or tunes alerts around them. OWASP lists unmonitored application and API logs, ineffective thresholds, and the inability to detect or escalate attacks in real time or near real time. This is the classic warehouse of evidence problem: data exists, but it has no operational value at the moment of attack.
Recent SOC data shows how widespread this remains. Splunk's 2025 State of Security research found that 59% of organizations say they have too many alerts, 55% deal with too many false positives, and 57% lose valuable investigation time to data management gaps. In other words, the problem is not only absence of logs. It is failure to convert logging into high fidelity monitoring that analysts can actually use.
4. Insecure Storage
A09 also includes failure to protect the integrity of logs. If attackers can alter, delete, or selectively suppress evidence, they can extend dwell time and damage trust in every later investigation. OWASP therefore calls for integrity controls such as append only audit trails, and GDPR Article 32 requires measures tied to confidentiality, integrity, availability, and resilience.
The Marriott penalty notice is a useful real world example because the ICO stated that regular and close monitoring and evaluation of logs can help early detection and mitigation, and discussed shortcomings in monitoring database activity and user actions on network devices. That makes A09 a storage and integrity problem as much as a visibility problem. If evidence is incomplete or weakly protected, the organization loses both early warning and post incident confidence.
5. Poor Retention
Poor retention means logs are deleted, rotated, or archived too soon for meaningful investigation, threat hunting, or regulatory review. OWASP requires sufficient retention for delayed forensic analysis, and PCI guidance emphasizes ongoing review and follow up on anomalies. When logs disappear before the breach is recognized, the timeline becomes guesswork.
This is especially dangerous because breach detection is often slow. IBM reports an average of 241 days to identify and contain a breach, and ChaosSearch notes that short retention windows undermine long range investigations and threat hunting. Retention therefore should be designed around likely detection delay, not just storage convenience.
6. No Centralization
No centralization means logs are scattered across applications, databases, cloud services, security tools, and support systems with no unified correlation layer. That prevents cross session, cross account, and cross device analysis, which is exactly what many modern fraud campaigns require to be detected. OWASP warns that adequate alerting use cases, escalation processes, and playbooks must exist; those become much harder when the telemetry is fragmented.
Operational data backs this up. Splunk found that 57% of organizations lose valuable investigation time due to data management gaps, while Elastic describes unified observability as combining logs, metrics, traces, and user experience data into one integrated platform for cross referenced analysis. Centralization does not guarantee detection, but without it, correlation becomes slow, partial, and expensive.
Real Examples of Security Logging and Alerting Failures
Target's 2013 breach remains one of the clearest demonstrations of how quickly a security incident becomes a business crisis when detection and response lag. Target later confirmed that guest information for up to 70 million individuals had been taken, and Reuters reported that the company eventually agreed to an $18.5 million multistate settlement. Even when an organization has large scale operations and brand recognition, poor visibility and delayed containment can turn one incident into a long and expensive chain of legal, financial, and trust consequences.
Yahoo
Yahoo is an equally important lesson because it shows that logging and alerting failures can evolve into governance and disclosure failures. The SEC said Yahoo agreed to pay a $35 million penalty after failing to disclose one of the world's largest data breaches, and the SEC stated that Yahoo did not properly investigate the breach and did not disclose it to investors until more than two years later. In A09 terms, this is the nightmare scenario: the organization has enough internal signal to suspect serious compromise, but not enough operational discipline to turn awareness into timely action.
Citrix
Citrix's 2019 incident also maps well to A09 because the initial external warning came from the FBI, not from internal detection. Citrix said the FBI contacted the company on March 6, 2019, and the company later confirmed the attackers gained access through password spraying and intermittently accessed internal systems from October 13, 2018 to March 8, 2019. That timeline shows why login telemetry, failed authentication patterns, device anomalies, and continuous monitoring matter so much. Attackers often do not need exotic malware if weak detection allows ordinary abuse patterns to persist for months.
Regulatory Compliance of Security Logging and Alerting Failures
Security logging and alerting failures have direct implications for both GDPR and PCI DSS because both frameworks assume organizations can detect, investigate, document, and respond to security incidents. GDPR Article 32 requires appropriate measures for ongoing confidentiality, integrity, availability, resilience, and regular testing and evaluation. GDPR Article 33 requires notification of a notifiable personal data breach within 72 hours where feasible, and documentation of breaches so supervisory authorities can verify compliance. The ICO also stresses that organizations should have robust breach detection, investigation, and internal reporting procedures in place, and should keep records of breaches even when notification is not required.
PCI DSS is even more explicit on logging operations. PCI guidance states that Requirement 10.6 covers review of logs and security events for all system components to identify anomalies or suspicious behavior, with daily log review for critical systems and follow up on exceptions and anomalies. The same guidance ties monitoring to formal response procedures and notes that designated personnel should be responsible for monitoring alerts and responding to security events on a 24 by 7 basis. In a payment environment, weak logging is not a documentation gap. It is a control failure.
Public fine examples illustrate the regulatory exposure. Reuters reports that the UK ICO fined British Airways £20 million over its 2018 data theft, and Reuters also reports that the ICO fined Marriott £18.4 million. The Marriott penalty notice is especially relevant to A09 because it explicitly discusses failure to monitor database activity and user actions, and says regular and close monitoring and evaluation of logs can assist in early detection, mitigation, and prevention of future attacks.
For PCI DSS, public fine structures are less standardized and less transparent because the PCI Security Standards Council says fines and penalties for noncompliance are defined by the payment card brands, not by PCI SSC itself. That means the public record is often richer for GDPR style enforcement than for PCI contractual penalties. Even so, the operational expectation is clear: if you process card data, you are expected to log, monitor, review, investigate, and respond.
Protection and Prevention Methods for Security Logging and Alerting Failures
This control means failed logins, authorization denials, validation failures, and similar security relevant events should be logged with user, timestamp, route, source, and supporting context that enable delayed forensic analysis. Developers usually implement the event schema, while security architects, fraud teams, and compliance leaders define what context is necessary and how long it must be retained. It is highly effective because many attacks first appear as repeated low level failures before they become confirmed incidents. The advantage is early visibility; the limitation is that large volumes accumulate quickly if the event model is noisy or badly scoped.
2. Log every security control, whether it succeeds or fails
OWASP recommends logging every part of the application that contains a security control, whether success or failure. That should be applied by engineering teams building authentication, step up checks, transaction approvals, device trust, and abuse prevention logic. Its effectiveness is high because successful abuse often looks like a valid event stream, not a blocked event stream. The benefit is complete narrative reconstruction; the drawback is that success events can become very high volume unless they are structured, prioritized, and analyzed intelligently.
3. Generate logs in formats log management systems can consume
Structured logs let SIEM, data lake, observability, and fraud analytics systems parse events consistently. This is mainly an engineering and platform team responsibility, although detection engineers and SOC teams should help define schemas that support alerting and investigation. It is effective because standardization improves correlation and automation across services and environments. The main benefit is speed and consistency; the main drawback is the upfront discipline required to normalize logging across legacy and modern systems.
4. Encode log data correctly to prevent attacks on the logging pipeline
Logs are not automatically safe just because they are defensive artifacts. OWASP warns that if log data is not encoded correctly, the logging or monitoring system itself may become vulnerable to injection or corruption. Developers, API engineers, and platform teams should apply this control because they control how untrusted input is transformed before storage or analysis. The benefit is integrity and safer downstream processing; the drawback is that inconsistent sanitization rules across languages and services can be hard to enforce.
5. Maintain audit trails with integrity controls
Audit trails should be tamper evident and resilient, for example through append only tables, immutable storage patterns, or other integrity controls. This is usually owned by platform engineering, security architecture, and database teams, but it matters just as much to compliance, fraud, and internal audit functions. It is very effective for investigations because it increases trust in the evidence and reduces the chance of silent log erasure. The tradeoff is cost and architectural complexity, especially in high volume environments.
6. Fail closed when transactions throw errors
OWASP recommends that transactions that throw an error be rolled back and started over, and that systems fail closed. This should be applied by application developers and solution architects in payment, identity, onboarding, and entitlement flows. It is effective because it prevents error states from becoming silent bypasses or partial commits that never trigger the right alert path. The benefit is safer transaction behavior; the drawback is that overly strict rollback logic can create user friction if error handling is not designed carefully.
7. Alert when application or user behavior becomes suspicious
Logging without alerting is one of the core failures inside A09. Developers, fraud teams, security analysts, and product owners should work together to define suspicious behaviors such as fail to success login flips, rapid account access, abnormal session navigation, impossible travel, unusual device changes, and risky profile edits. This control is highly effective when tied to real use cases because it converts passive records into operational response. The benefit is timely action; the drawback is alert fatigue if thresholds are static, generic, or poorly tuned.
8. Build monitoring use cases and playbooks for SOC response
OWASP explicitly says DevSecOps and security teams should establish effective monitoring and alerting use cases, including playbooks, so suspicious activities are detected and responded to quickly. This belongs to detection engineering, SOC operations, fraud operations, and incident response leadership. Its effectiveness is high because even accurate alerts lose value if teams do not know who owns them or what action to take next. The benefit is faster triage and cleaner escalation; the drawback is that playbooks decay if they are not updated continuously.
9. Use honeytokens to create high fidelity detections
Honeytokens are deliberately unused credentials, records, or identity artifacts placed where legitimate business activity should never touch them. OWASP recommends them because access to these artifacts generates alerts with very low false positive rates. Security teams, fraud teams, and identity teams are usually best placed to deploy them. The advantage is signal quality; the limitation is that honeytokens detect specific adversary behavior, not the full attack surface.
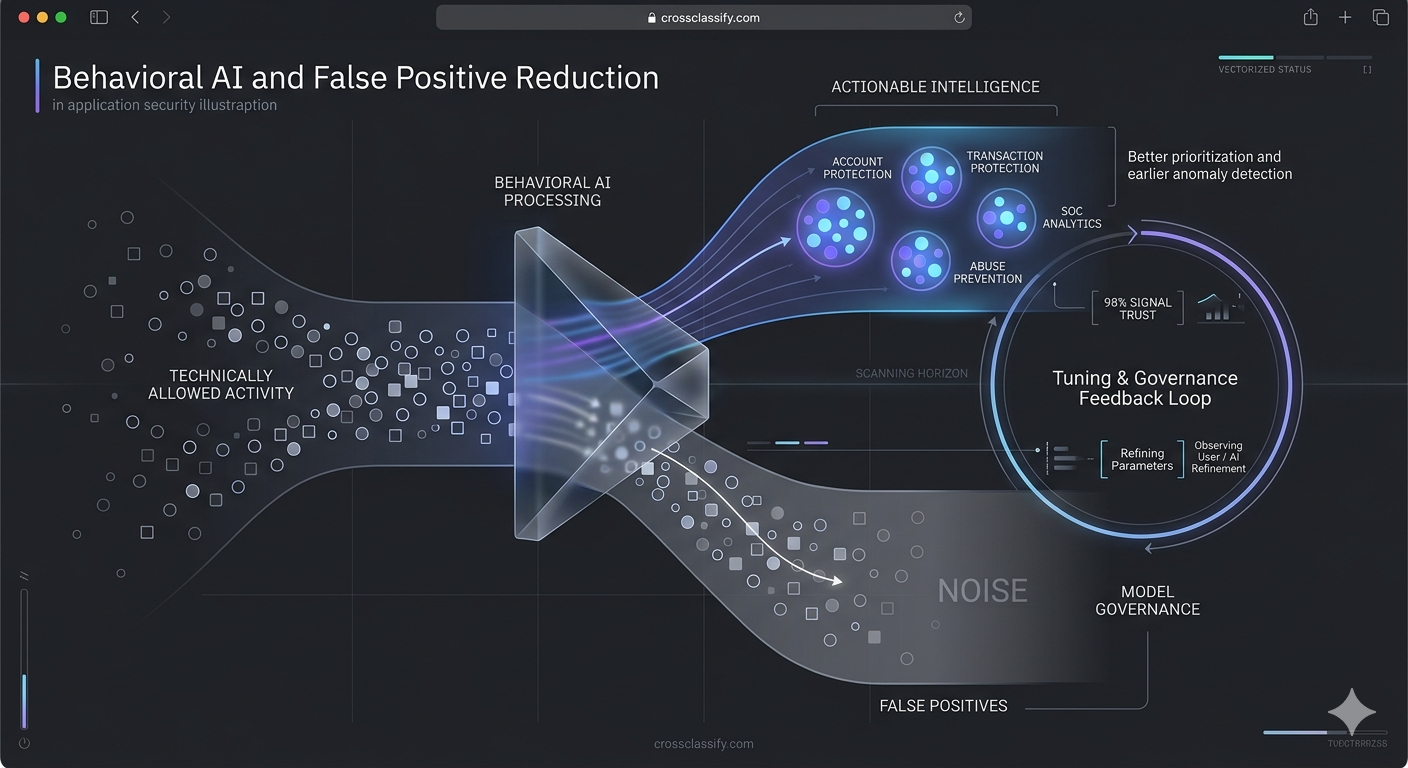
10. Add behavior analysis and AI to reduce false positives and improve detection
OWASP specifically notes that behavior analysis and AI can support lower false positive rates. This is where modern fraud prevention and modern application security begin to converge, because behavior based detection is better at spotting suspicious but technically allowed activity. It should be applied by teams responsible for account protection, transaction protection, SOC analytics, and abuse prevention. The benefit is better prioritization and earlier anomaly detection; the drawback is that models must be tuned, monitored, and governed so teams trust the signal.
OWASP recommends adopting an incident response and recovery plan, and educating developers on what application attacks and incidents look like. This is not just a SOC function, because engineers, product owners, and support teams often see the first operational symptoms of abuse. It is effective because A09 failures are often multiplied by poor escalation and unclear ownership. The benefit is organizational readiness; the drawback is that plans that are never rehearsed become shelf documents rather than working controls.
Protection Tools for Security Logging and Alerting Failures
Dynamic Application Security Testing is relevant to A09 because OWASP explicitly says penetration testing and DAST scans such as Burp or ZAP should trigger alerts. If the application is scanned and the monitoring stack stays silent, the organization has learned something important and uncomfortable about its visibility gaps. DAST therefore supports A09 not only by finding weaknesses, but also by validating whether detection content is alive.
OWASP ZAP is a strong open source option because it is widely used, free, and designed for web application scanning and automation. Its active scan feature uses known attacks against selected targets, which makes it useful for testing whether security telemetry and alerting pipelines react when exposed to suspicious patterns. Burp Scanner plays a similar role in commercial environments, with automated crawling and auditing that replicate the behavior of a skilled tester across modern applications.
For runtime protection, OWASP CRS and ModSecurity remain relevant. OWASP describes CRS as a set of generic attack detection rules for use with ModSecurity or compatible WAFs, designed to protect against a broad range of attacks with minimal false alerts. That does not replace behavioral monitoring, but it gives teams a first defensive layer that can also feed alerting and correlation pipelines.
For storage, correlation, and operational visibility, ELK and similar observability stacks are useful because they centralize logs and make cross referenced analysis possible. Elastic describes its observability platform as combining logs, metrics, traces, and user experience data into a single integrated platform. In A09 terms, this helps move from isolated records toward actionable incident context.
The Gap That Still Exists After You Start Logging Everything
Many teams believe they have solved A09 once they can prove that almost every event is being recorded. In reality, that is only the first half of the problem. Storage is no longer the hardest part for most modern organizations. Cloud systems, lakes, and observability stacks can retain huge volumes of events at scale. The real challenge is finding the one meaningful anomaly inside a mountain of ordinary activity, then recognizing it early enough to stop fraud, contain abuse, or escalate the right response.
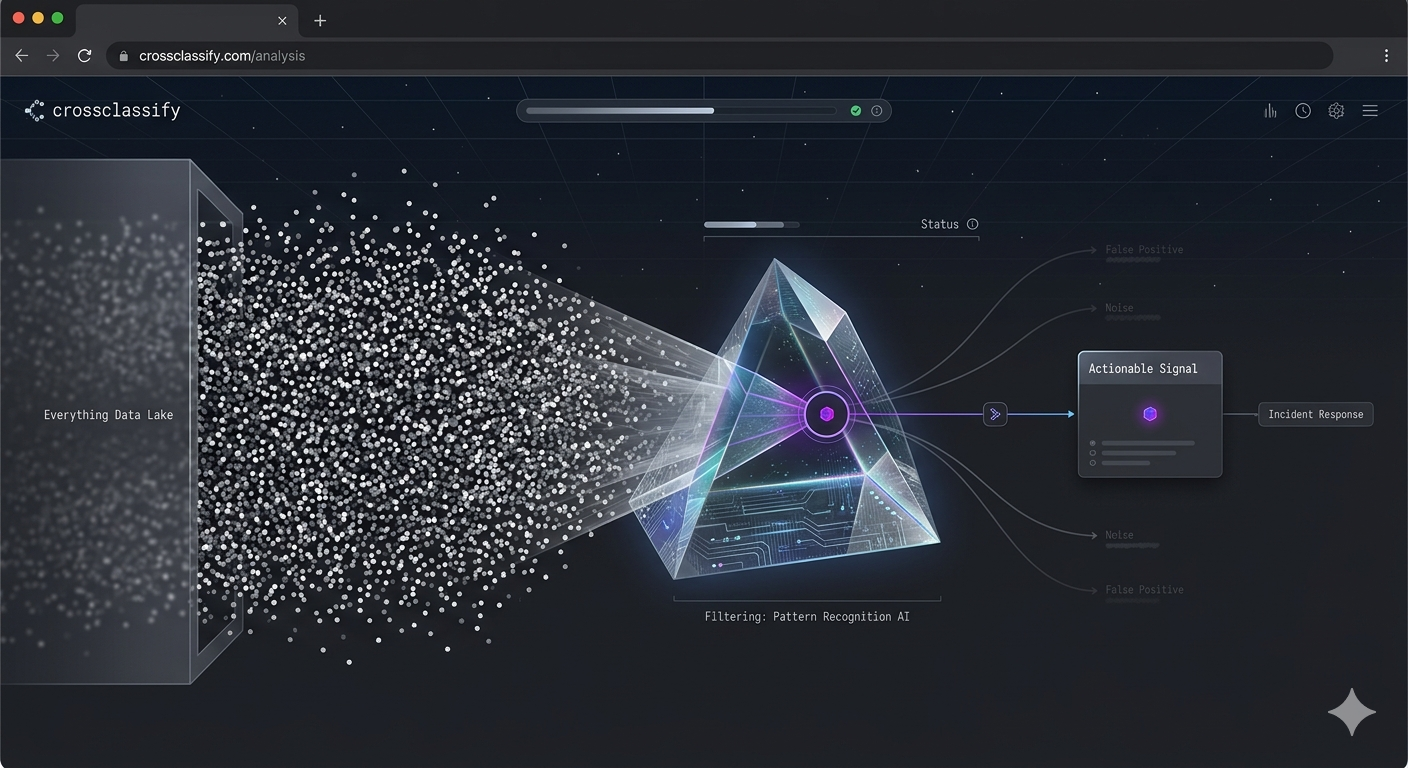
This is exactly where traditional logging programs begin to fail. Splunk's 2025 research shows that 59% of organizations say they have too many alerts, 55% struggle with false positives, and 57% lose valuable investigation time because of data management gaps. So the modern A09 challenge is not simply “log more.” It is “continuously interpret what matters.” Static thresholds and rule sets help, but they do not adapt well when attackers use valid credentials, mimic normal navigation, or spread abuse across low intensity signals.
This is why the strongest response to A09 now combines continuous monitoring, adaptive trust evaluation, device intelligence, and behavioral analysis. CrossClassify's own material frames this well: its CARTA article describes real time, context aware, adaptive decision making; its behavior based materials emphasize continuous authentication and anomaly detection; and its article on what WAF and MFA miss explains why valid looking sessions still need ongoing scrutiny after the perimeter approves them. The gap, then, is not event collection. The gap is intelligent and adaptive event interpretation.
Continuous Monitoring and Continuous Adaptive Risk and Trust Assessment
Continuous Adaptive Risk and Trust Assessment, CARTA, is a strong fit for A09 because A09 is fundamentally about delay, ambiguity, and missed escalation. CrossClassify describes CARTA as an approach that constantly evaluates user behavior, device context, and system anomalies, then adapts trust and controls dynamically rather than relying on one time checks. For Security Logging and Alerting Failures, that means the system no longer treats logs as passive history. It treats them as live input to changing trust decisions.
This matters because OWASP A09 explicitly mentions the inability to detect, escalate, or alert for active attacks in real time or near real time. CARTA is built for that exact gap. Instead of waiting for a post incident query in a SIEM, a CARTA style model turns abnormal device changes, rapid navigation, impossible travel, unusual transaction timing, or fail to success sequences into updated risk scores during the session itself. That shortens the window between suspicious activity and defensive action.
In practical product terms, CARTA gives application owners a cleaner way to align security and user experience. Trusted behavior can remain low friction, while risky sessions can trigger step up checks, temporary holds, or analyst review. That is much closer to the modern reality of fraud and application abuse, where attackers often pass the front door and only reveal themselves through what they do next. For deeper internal linking on this model, the relevant CrossClassify resource is Continuous Adaptive Risk and Trust Assessment, which connects adaptive security decisions to ongoing behavior and device analysis.
Continuous Monitoring of Device and Behavioral Biometrics
Device fingerprinting should sit near the center of a serious A09 protection platform because logs without persistent identity context are much harder to correlate. CrossClassify's device intelligence material explains that continuous device monitoring correlates hardware and software attributes to build a device identity that is resistant to evasion and spoofing, enabling detection across sessions even when IPs, browsers, or cookies change. For A09, this upgrades ordinary event logs into device aware event streams. Instead of seeing isolated requests, the system can see whether a supposedly trusted account has suddenly switched into an unfamiliar device pattern or an evasion pattern.
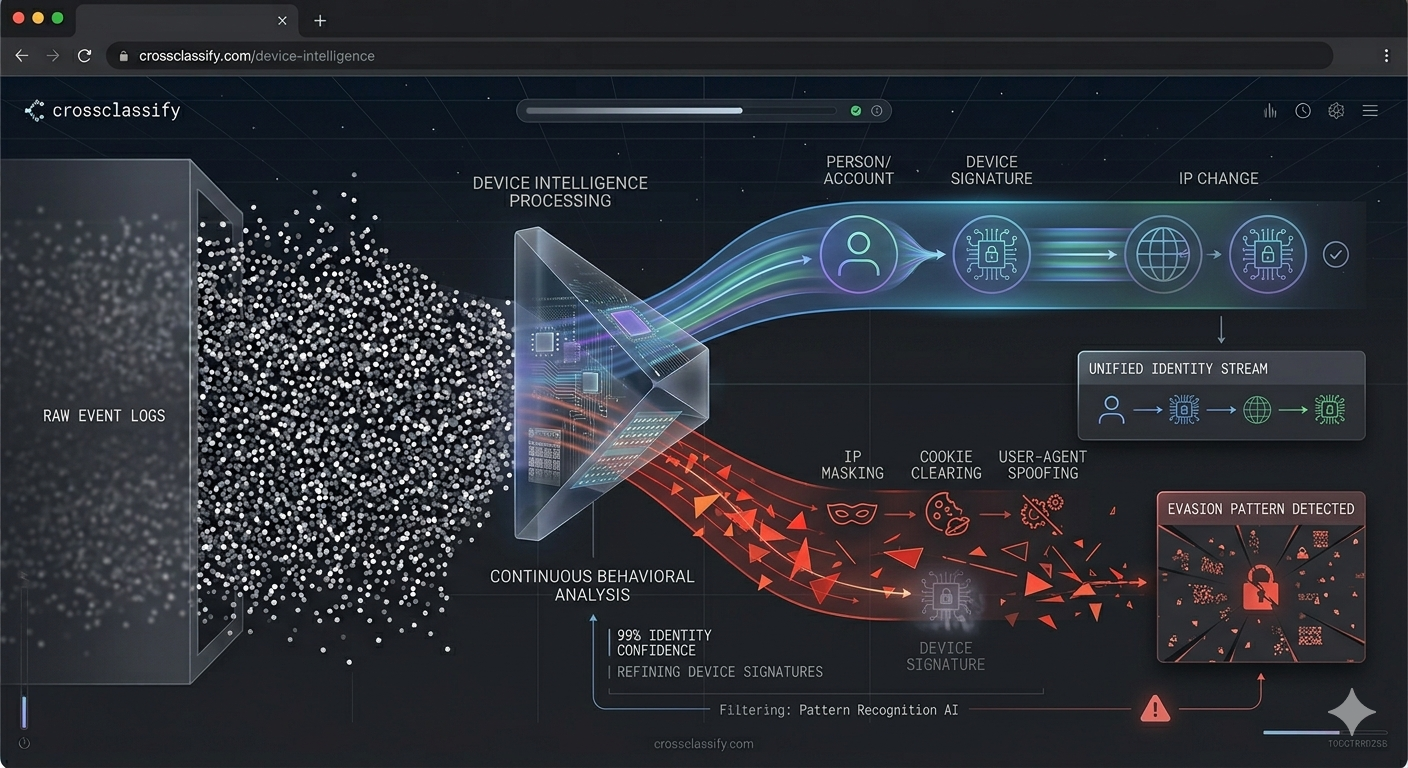
Behavioral biometrics adds the second half of the picture. CrossClassify describes behavioral biometrics as continuous authentication and passive background monitoring of how a person types, swipes, scrolls, moves, and navigates. It also describes alerting on behavioral thresholds such as fail to success login flips, payout edits, device binding breaks, and other risky sequences. This is exactly the kind of evidence A09 needs because many dangerous sessions are technically valid but behaviorally wrong.
The strongest result comes from combining both layers. CrossClassify's materials repeatedly emphasize the value of fusing device fingerprinting with behavioral analysis to reduce false positives and improve detection accuracy. In A09 language, that means fewer empty alerts, better correlation, and higher confidence when the system says, “this event is not just unusual, it is likely malicious.” If the objective is to continuously monitor varied ranges of logs and flag even small red signals, device identity plus behavioral biometrics is far stronger than raw event volume alone. For the relevant internal pages, see Device Fingerprinting and Behavioral Biometrics.
Necessity of Continuous Monitoring of Device Fingerprinting and Behavioral Biometrics
The necessity is simple: modern attackers frequently look legitimate at the moment of entry. They may use stolen credentials, a previously seen network path, a real customer account, or a session that already passed MFA. In those situations, more logging by itself does not protect the application owner. What protects the owner is the ability to continuously evaluate whether the ongoing activity still matches the expected device, expected rhythm, expected session path, and expected trust posture.
That makes device fingerprinting and behavioral biometrics especially important for the concerns inside A09. They help transform logs from static records into interpretable behavioral evidence. Device fingerprinting gives continuity across sessions and evasion attempts, while behavioral biometrics gives continuity across actions and intent signals. Together, they make alerting more precise and response more defensible.
This also aligns with broader Zero Trust thinking. CrossClassify's Zero Trust material emphasizes context aware controls across identity, devices, behavior, and real time analytics rather than simple perimeter trust. For A09, that is the practical future: not endless raw telemetry, but security telemetry that continuously answers whether this user, on this device, in this session, is still trustworthy. The safer digital world is not the one with the most logs. It is the one with the most adaptive understanding of what those logs mean. For related internal reading, see Zero Trust Architecture and Modern AI Cybersecurity.
Conclusion
OWASP A09:2025 Security Logging and Alerting Failures is easy to underestimate because it rarely looks dramatic in architecture diagrams. Yet in real incidents it often becomes the reason attackers stay invisible, investigations stay incomplete, alerts arrive too late, and compliance obligations become much harder to satisfy. Official OWASP guidance, GDPR requirements, PCI DSS monitoring expectations, and major breach history all point to the same conclusion: visibility without interpretation is not enough.
The next step for application owners is to move from passive logging to continuous trust evaluation. That is why device fingerprinting, behavioral biometrics, and CARTA style monitoring are so relevant to this OWASP branch. They help security teams identify the subtle anomalies that static rules, WAFs, and one time authentication checks can miss, especially in account takeover, account opening fraud, bot abuse, and post login session abuse.
For internal linking inside the CrossClassify ecosystem, the most relevant pages for this article are Zero Trust Architecture and Modern AI Cybersecurity, Continuous Adaptive Risk and Trust Assessment, Behavioral Biometrics, and Device Fingerprinting. Those resources let you extend the article from OWASP education into implementation guidance that is directly relevant for modern fraud prevention and adaptive application defense.
The deeper message is that A09 is no longer just about whether logs exist. It is about whether an application can continuously recognize suspicious identity behavior, suspicious device behavior, suspicious workflow behavior, and suspicious session behavior in time to matter. That is the real gap still left open in many security programs, and it is exactly where a platform like CrossClassify can add the most value when the article transitions from theory into solution.
See How CrossClassify Uses Behavioral Biometrics to Detect Fraud
Analyze real user behavior patterns continuously to uncover suspicious sessions with less friction

Explore CrossClassify today
Detect and prevent fraud in real time
Protect your accounts with AI-driven security
Try CrossClassify for FREE—3 months
Share in
Related articles


Frequently asked questions
Let's Get Started
Create your free
account today
Discover how to secure your app against fraud using CrossClassify
No credit card required